BIG DATA is getting Bigger and Bigger
BIG DATA Getting Started with HADOOP
BIG DATA Cloudera and Oracle
BIG DATA CDH Single Node Setup
BIG DATA HADOOP Services Startup and Shutdown
BIG DATA Moving a file to HDFS
BIG DATA HADOOP Testing with MapReduce Examples Part 1
BIG DATA HADOOP Testing with MapReduce Examples Part 2
BIG DATA HADOOP Testing with MapReduce Examples Part 3
In BIG DATA HADOOP Testing with MapReduce Examples Part 1 and BIG DATA HADOOP Testing with MapReduce Examples Part 2 I have resolved some of the issues in getting the HADOOP running but still I have some issues left over and this time it is "Invalid shuffle port number -1 returned" when the mapreduce jobs are submitted.
hadoop@bigdataserver1:~/hadoop> hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.0.0-cdh4.2.0.jar wordcount /bigdata1/name.txt /bigdata1/output
13/03/13 14:59:38 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
13/03/13 14:59:39 INFO service.AbstractService: Service:org.apache.hadoop.yarn.client.YarnClientImpl is inited.
13/03/13 14:59:39 INFO service.AbstractService: Service:org.apache.hadoop.yarn.client.YarnClientImpl is started.
13/03/13 14:59:40 INFO input.FileInputFormat: Total input paths to process : 1
13/03/13 14:59:41 INFO mapreduce.JobSubmitter: number of splits:1
13/03/13 14:59:41 WARN conf.Configuration: mapred.jar is deprecated. Instead, use mapreduce.job.jar
13/03/13 14:59:41 WARN conf.Configuration: mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
13/03/13 14:59:41 WARN conf.Configuration: mapreduce.combine.class is deprecated. Instead, use mapreduce.job.combine.class
13/03/13 14:59:41 WARN conf.Configuration: mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
13/03/13 14:59:41 WARN conf.Configuration: mapred.job.name is deprecated. Instead, use mapreduce.job.name
13/03/13 14:59:41 WARN conf.Configuration: mapreduce.reduce.class is deprecated. Instead, use mapreduce.job.reduce.class
13/03/13 14:59:41 WARN conf.Configuration: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
13/03/13 14:59:41 WARN conf.Configuration: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
13/03/13 14:59:41 WARN conf.Configuration: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
13/03/13 14:59:41 WARN conf.Configuration: mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
13/03/13 14:59:41 WARN conf.Configuration: mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
13/03/13 14:59:41 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1363184126427_0001
13/03/13 14:59:41 INFO client.YarnClientImpl: Submitted application application_1363184126427_0001 to ResourceManager at /0.0.0.0:8032
13/03/13 14:59:42 INFO mapreduce.Job: The url to track the job: http://bigdataserver1:8088/proxy/application_1363184126427_0001/
13/03/13 14:59:42 INFO mapreduce.Job: Running job: job_1363184126427_0001
13/03/13 14:59:53 INFO mapreduce.Job: Job job_1363184126427_0001 running in uber mode : false
13/03/13 14:59:53 INFO mapreduce.Job: map 0% reduce 0%
13/03/13 14:59:54 INFO mapreduce.Job: Task Id : attempt_1363184126427_0001_m_000000_0, Status : FAILED
Container launch failed for container_1363184126427_0001_01_000002 : java.lang.IllegalStateException: Invalid shuffle port number -1 returned for attempt_1363184126427_0001_m_000000_0
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:170)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java:399)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:619)
13/03/13 14:59:55 INFO mapreduce.Job: Task Id : attempt_1363184126427_0001_m_000000_1, Status : FAILED
Container launch failed for container_1363184126427_0001_01_000003 : java.lang.IllegalStateException: Invalid shuffle port number -1 returned for attempt_1363184126427_0001_m_000000_1
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:170)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java:399)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:619)
13/03/13 14:59:57 INFO mapreduce.Job: Task Id : attempt_1363184126427_0001_m_000000_2, Status : FAILED
Container launch failed for container_1363184126427_0001_01_000004 : java.lang.IllegalStateException: Invalid shuffle port number -1 returned for attempt_1363184126427_0001_m_000000_2
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:170)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java:399)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:619)
13/03/13 14:59:59 INFO mapreduce.Job: map 100% reduce 0%
13/03/13 14:59:59 INFO mapreduce.Job: Job job_1363184126427_0001 failed with state FAILED due to: Task failed task_1363184126427_0001_m_000000
Job failed as tasks failed. failedMaps:1 failedReduces:0
13/03/13 15:00:00 INFO mapreduce.Job: Counters: 4
Job Counters
Other local map tasks=3
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=0
Total time spent by all reduces in occupied slots (ms)=0
hadoop@bigdataserver1:~/hadoop>
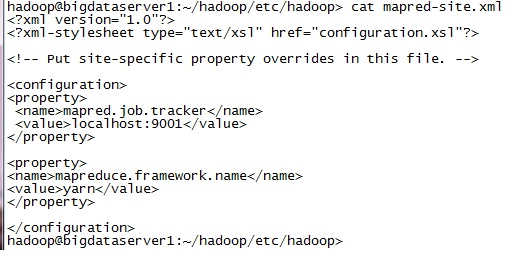
Solution is to update yarn-site.xml with the values below and then restart the HADOOP cluster.

hadoop@bigdataserver1:~/hadoop> hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.0.0-cdh4.2.0.jar wordcount /bigdata1/name.txt /bigdata1/output4
13/03/13 15:23:14 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
13/03/13 15:23:15 INFO service.AbstractService: Service:org.apache.hadoop.yarn.client.YarnClientImpl is inited.
13/03/13 15:23:15 INFO service.AbstractService: Service:org.apache.hadoop.yarn.client.YarnClientImpl is started.
13/03/13 15:23:16 INFO input.FileInputFormat: Total input paths to process : 1
13/03/13 15:23:16 INFO mapreduce.JobSubmitter: number of splits:1
13/03/13 15:23:16 WARN conf.Configuration: mapred.jar is deprecated. Instead, use mapreduce.job.jar
13/03/13 15:23:16 WARN conf.Configuration: mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
13/03/13 15:23:16 WARN conf.Configuration: mapreduce.combine.class is deprecated. Instead, use mapreduce.job.combine.class
13/03/13 15:23:16 WARN conf.Configuration: mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
13/03/13 15:23:16 WARN conf.Configuration: mapred.job.name is deprecated. Instead, use mapreduce.job.name
13/03/13 15:23:16 WARN conf.Configuration: mapreduce.reduce.class is deprecated. Instead, use mapreduce.job.reduce.class
13/03/13 15:23:16 WARN conf.Configuration: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
13/03/13 15:23:16 WARN conf.Configuration: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
13/03/13 15:23:16 WARN conf.Configuration: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
13/03/13 15:23:16 WARN conf.Configuration: mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
13/03/13 15:23:16 WARN conf.Configuration: mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
13/03/13 15:23:16 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1363188167312_0001
13/03/13 15:23:17 INFO client.YarnClientImpl: Submitted application application_1363188167312_0001 to ResourceManager at /0.0.0.0:8032
13/03/13 15:23:17 INFO mapreduce.Job: The url to track the job: http://bigdataserver1:8088/proxy/application_1363188167312_0001/
13/03/13 15:23:17 INFO mapreduce.Job: Running job: job_1363188167312_0001
13/03/13 15:23:27 INFO mapreduce.Job: Job job_1363188167312_0001 running in uber mode : false
13/03/13 15:23:27 INFO mapreduce.Job: map 0% reduce 0%
13/03/13 15:23:32 INFO mapreduce.Job: map 100% reduce 0%
13/03/13 15:23:38 INFO mapreduce.Job: map 100% reduce 100%
13/03/13 15:23:38 INFO mapreduce.Job: Job job_1363188167312_0001 completed successfully
13/03/13 15:23:38 INFO mapreduce.Job: Counters: 43
File System Counters
FILE: Number of bytes read=2369
FILE: Number of bytes written=140677
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1474
HDFS: Number of bytes written=1631
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3851
Total time spent by all reduces in occupied slots (ms)=4999
Map-Reduce Framework
Map input records=200
Map output records=199
Map output bytes=2165
Map output materialized bytes=2369
Input split bytes=104
Combine input records=199
Combine output records=183
Reduce input groups=183
Reduce shuffle bytes=2369
Reduce input records=183
Reduce output records=183
Spilled Records=366
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=57
CPU time spent (ms)=2730
Physical memory (bytes) snapshot=358436864
Virtual memory (bytes) snapshot=926806016
Total committed heap usage (bytes)=303431680
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1370
File Output Format Counters
Bytes Written=1631
hadoop@bigdataserver1:~/hadoop>
Finally I have verified my HADOOP cluster.